
产品介绍
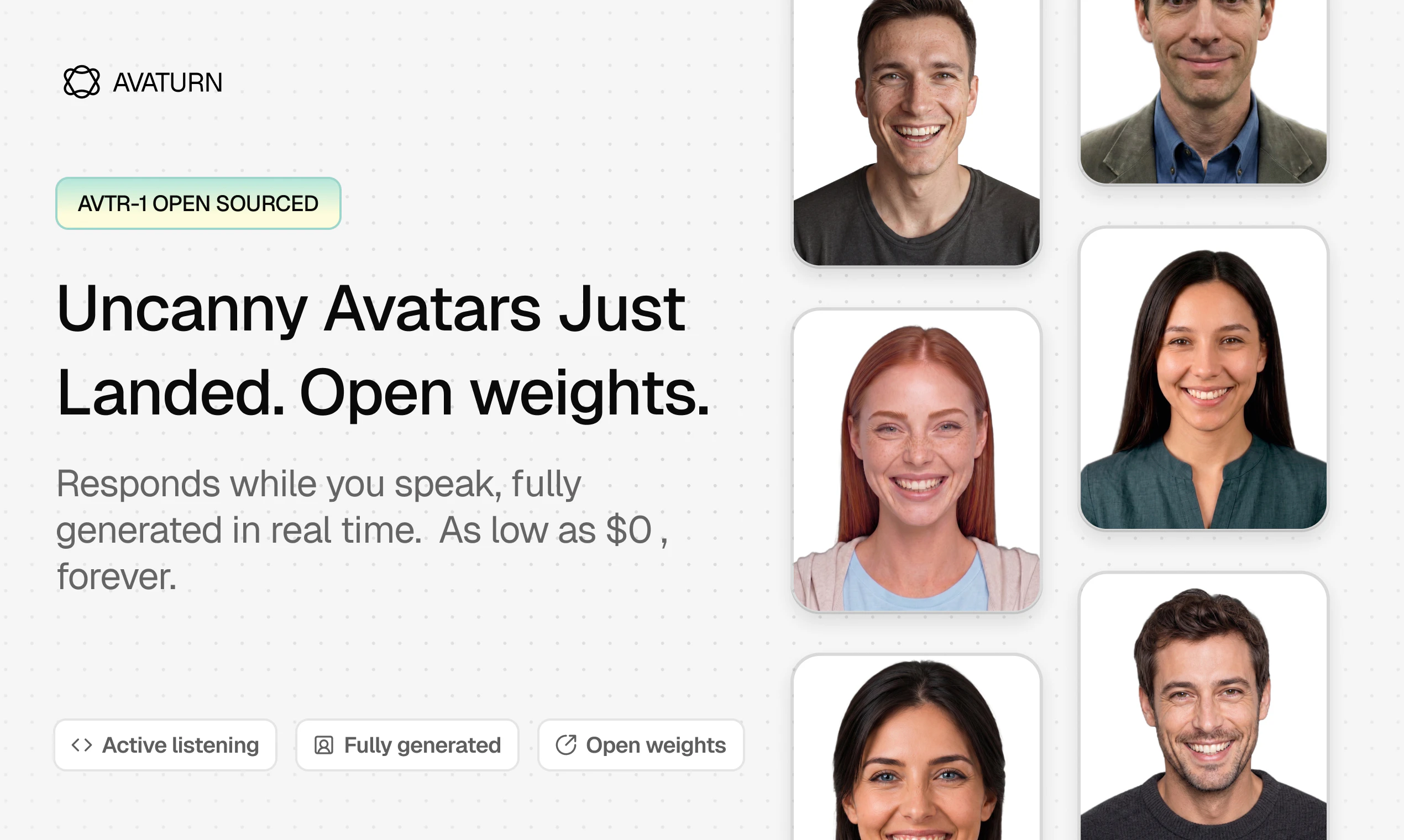
全球最优秀的实时数字人模型现已开源并开放权重。可以自由获取模型、调优并以零成本使用。独特之处在于:模型支持全双工通信,在对话过程中持续倾听并实时响应,延迟极低。每一帧画面都是实时生成的,彻底避免了预录制回放带来的动画循环感。同时附带完整的流式基础设施,开箱即用。
适合谁关注
- 开发者和技术团队
- 设计师、内容创作者和视觉团队
- 正在评估 AI 工具或智能体落地的团队
可借鉴场景
- 快速理解 AVTR-1 Real-Time Open Weights Model 的定位、核心能力和 Product Hunt 热度
- 判断“生成逼真 AI 数字人的模型现已开源”这类需求是否值得做竞品调研
- 沿着 视频流、开发者工具 继续发现同类产品和替代方案
- 筛选高票产品,观察海外用户当前愿意投票支持的产品形态
- 结合评论热度,判断该产品是否有真实讨论和早期用户反馈
148
投票数
15
评论数
5月26日
发布日期
作者自荐
总结
AVTR-1 的发布标志着实时 AI 数字人领域迈入开源时代。与传统方案在预录视频上叠加口型不同,AVTR-1 实现了逐帧全脸生成,彻底消除了动画循环的违和感。全双工架构使数字人能在对话中实时响应语气和情绪变化,交互体验更接近真人。在硬件门槛上,单张 A100 或消费级 4060 即可实现端到端 200 毫秒以内延迟,大幅降低了部署成本。开放权重加上配套的流式基础设施 Avaturn Streamer,为开发者提供了即插即用的完整方案。年收入 1000 万美元以下免费的许可策略也有助于快速扩展生态。不过,开源模型的质量控制、滥用风险以及与闭源商业方案的性能差距仍是需要持续关注的挑战。
GitMemo免费开源
把 AI 对话保存到你的 Git 知识库
本地优先,支持 macOS 与 Android。剪贴板、截图、笔记和文件都能集中保存、搜索、同步。
获取安装包
大家好,Product Hunt 👋 我是 Sergei Sherman,@Avaturn 的 CEO。 今天正式发布 AVTR-1——一个开放权重的实时 AI 数字人模型,在关键基准测试上达到了全新的业界最佳水平。 如果正在构建任何与实时 AI 数字人相关的应用,AVTR-1 值得关注。 ✍️ AVTR-1 的独特之处: 整张脸都是生成的。不是在预录制片段上替换嘴唇,而是从头顶到下巴,数字人面部的每一个像素都在逐帧实时生成。 原生全双工——数字人会主动倾听。模型全程持续生成画面,无论数字人是在说话还是倾听。就像真人通话一样,数字人的面部会实时回应对方的话语和语调。如果第三个词语气带有惊讶,眉毛就会在第三个词时扬起,而不是等整句话说完。 三年来,所谓"实时数字人"一直意味着在预录视频上贴一张生成的嘴。这次彻底抛弃了预录方案。 🎯 选择 AVTR-1 的理由: 开放权重。个人、研究及年收入低于 1000 万美元的商业用途完全免费。超出部分可通过商业许可获取。 在单张 A100 或 4060 上端到端延迟低于 200 毫秒。支持在本地设备、数据中心或云端运行。 附带 Avaturn Streamer——面向实时数字人的开源基础设施层。可将 AVTR-1 或任何其他开放权重实时视频模型作为即插即用组件接入。一端接入视频模型,另一端接入对话后端。 开箱即用的参考数字人形象。模型卡片齐全、许可证清晰,今天即可部署。 仓库中包含与 Cartesia 和 Pipecat 的首日联合示例。 🏗️ 有一件事明确表示本次不会发布——但希望行业共同参与建设: 一个公开的、厂商中立的实时 AI 数字人排行榜。这个品类需要一个透明的计分板,由整个生态共同运营。只有清晰、公开的竞争才能推动快速进步。 诚邀每一位厂商、开源贡献者和研究者一起来构建它。 🎉 所有内容今天全部上线: 代码、推理、评估:github.com/avaturn-live/avtr-1 模型权重下载:huggingface.co/avaturn-live/avtr-1 技术报告、完整论文、可复现基准测试:avtr-1.avaturn.live 在线演示:avaturn.live 实时生成视频是下一个前沿。之前的每一波浪潮——文本,然后是实时音频——都产生了一个开放层供整个品类构建。今天发布的正是这个层:模型和编排基础设施全部就绪。 欢迎在下方留下问题、反馈或正在构建的项目——我会全天在线 🚀 — Sergei